deforderSequentialSearch(iters,item): found = False for i in iters: if i == item: found = True break if i > item: break
return found
二分搜索
有序列表的二分搜索
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defbinarySearch(iters,item): found = False front = 0 after = len(iters) - 1
while found != Trueand after>=front: middle = (after + front) // 2 if iters[middle] == item: found = True elif iters[middle] < item: front = middle+1 else: after = middle-1 return found
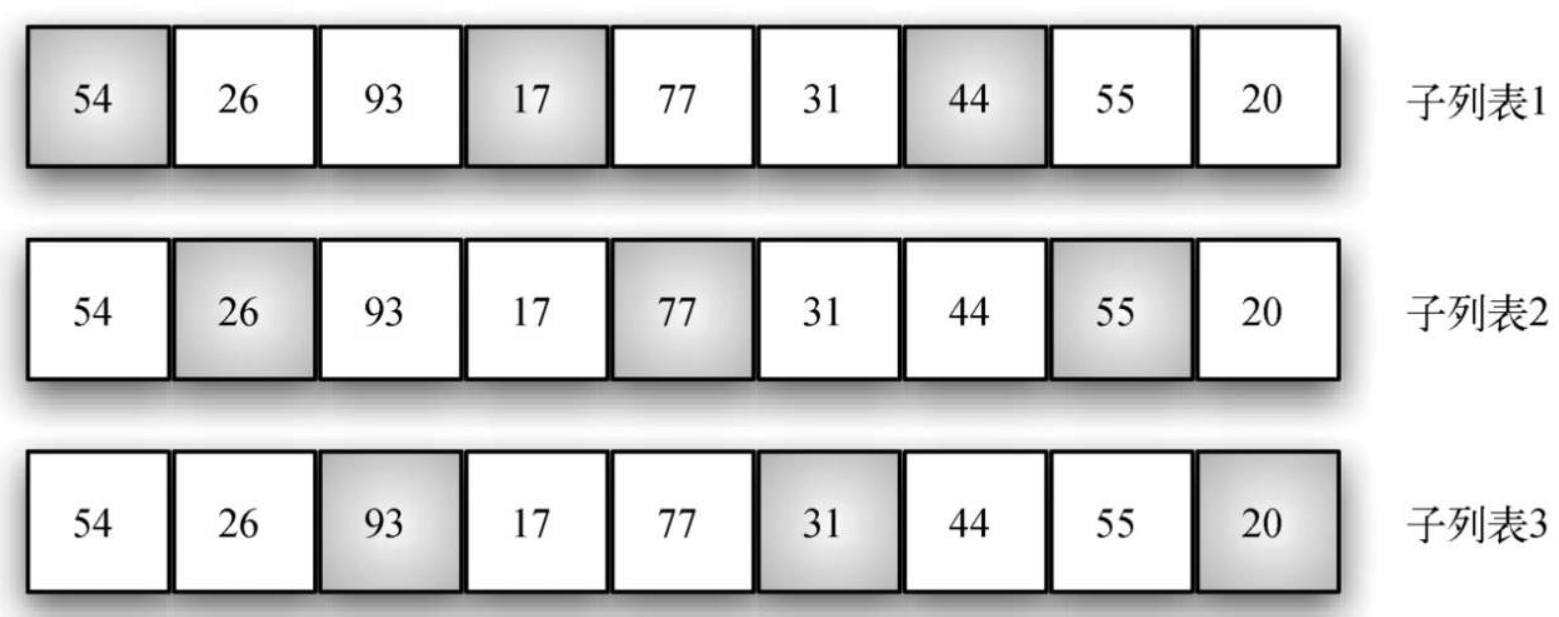
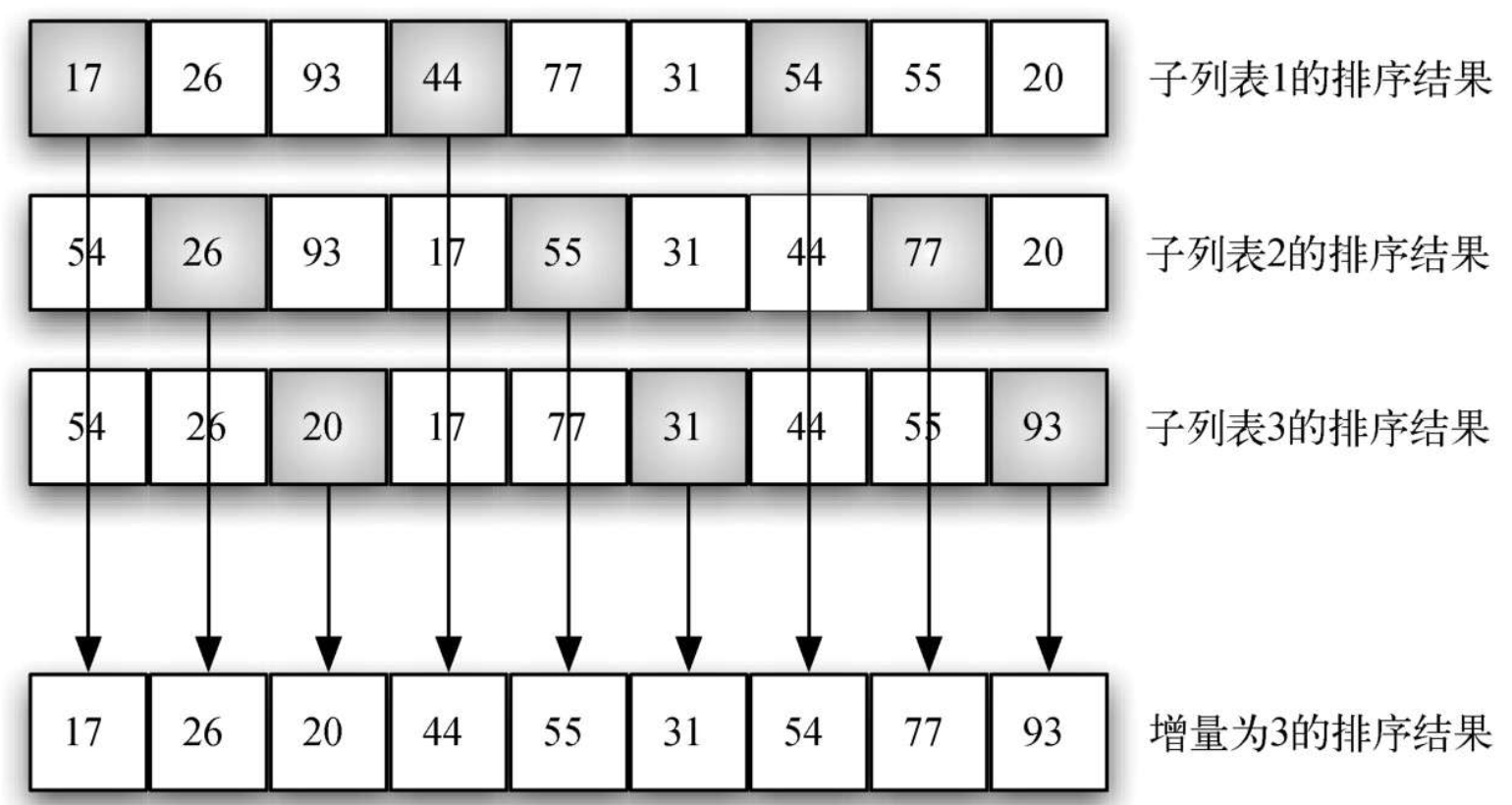
defshellSort(alist): sublistcount = len(alist)//2 while sublistcount > 0: for startpoint inrange(sublistcount): getInsertionSort(alist,startpoint,sublistcount)
sublistcount = sublistcount//2
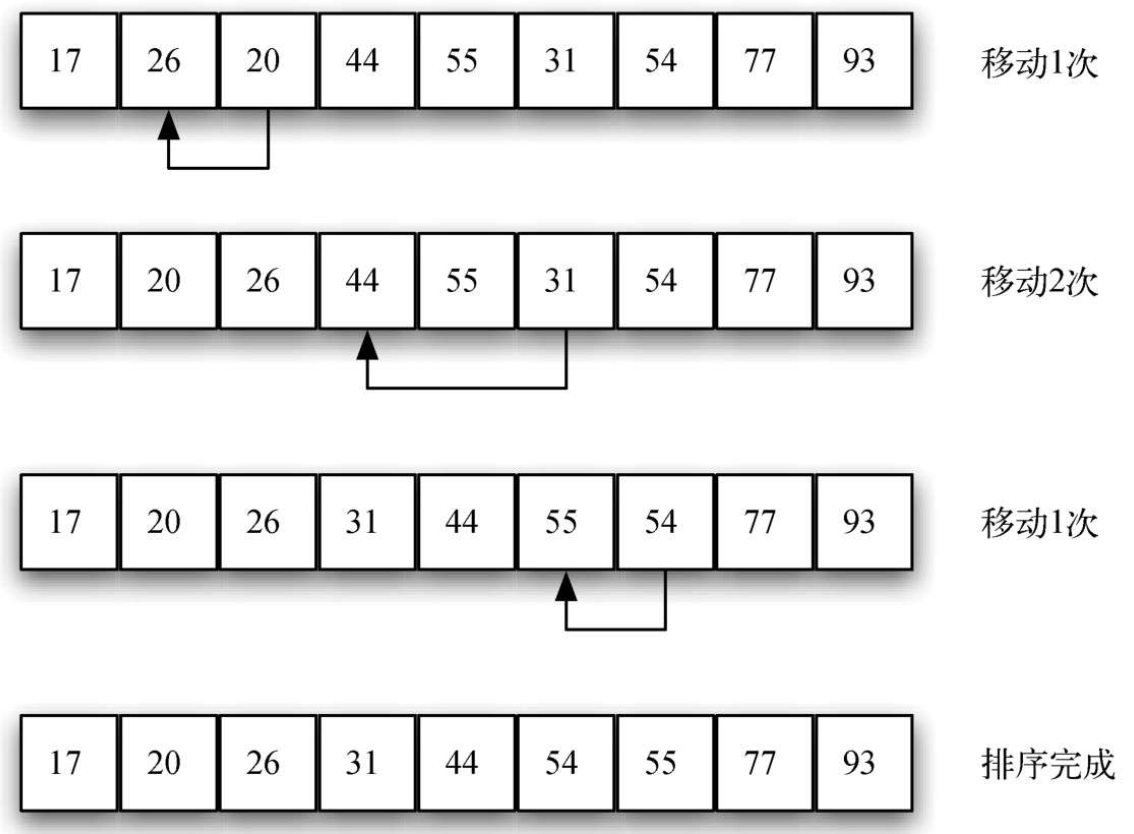
defgetInsertionSort(alist,start,gap): for i inrange(start+gap,len(alist),gap): currentValue = alist[i] position = i for j inrange(i-gap,-1,-gap): if alist[j] > currentValue: alist[j+gap] = alist[j] position = position-gap else: break alist[position] = currentValue
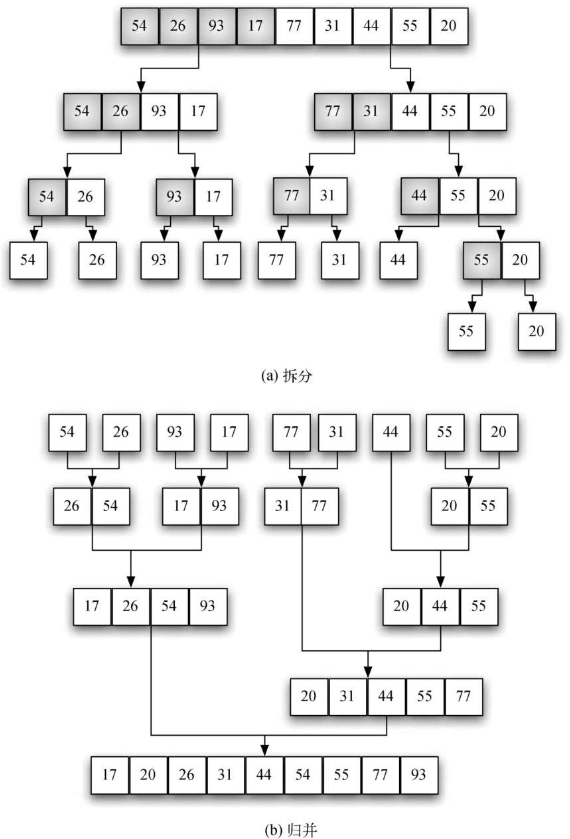
i = 0 j = 0 k = 0 while i < len(lefthalf) and j < len(righthalf): if lefthalf[i] < righthalf[j]: alist[k] = lefthalf[i] i += 1 else: alist[k] = righthalf[j] j += 1 k += 1
while i < len(lefthalf): alist[k] = lefthalf[i] i += 1 k += 1
while j < len(righthalf): alist[k] = righthalf[j] j += 1 k += 1



 wechat
wechat